

Inicio con este post una serie más o menos extensa de artículos de carácter algo técnico sobre aprendizaje por refuerzo (‘reinforcement learning‘), una serie en que iré recogiendo aspectos que me parecen claves o interesantes de este mecanismo de aprendizaje propio del campo de la inteligencia artificial.
Inciso: El porqué y el cómo de unas notas sobre aprendizaje por refuerzo
¿Por qué dedicarle toda una serie de posts al tema del aprendizaje por refuerzo’
Bueno, se trata de una de las formas fundamentales de aprendizaje y, además, la que parece estar más cercana a la forma de razonar humana. Una forma de aprendizaje, también, mucho más económica en datos y, cabe pensar, que por ende en consumo energético.
Una forma de aprendizaje, además, que está presente, por ejemplo, en el entrenamiento de modelos generativos tipo GPT y, una forma de aprendizaje muy interesante, probablemente central, para la consecución de agentes autónomos inteligentes, incluyendo robots cognitivos avanzados y llegando a los robots humanoides, temas a los que, como expresé en el post ‘Los robots, el inicio de curso y los cantos de sirena‘ tengo interés en dedicar tiempo de estudio e investigación.
Y me decido a convertir parte de ese estudio en una serie de posts por dos motivos: por una parte porque el escribirlo me ayuda a mí mismo a simplificar, estructurar e incluso asimilar los mensajes, por otro, porque espero que, al menos a una parte de la audiencia de este blog, le pueda resultar muy interesante.
No tengo un plan cerrado de cuántos posts compondrán la serie ni los temas concretos de cada post. Los iré publicando a medida que vaya identificando aspectos que creo conviene explicar, y a medida que avanzo en la lectura del libro ‘Deep reinforcement learning‘ de Aske Plaat que utilizaré como base.
No quiere esto decir que todos los posts de Blue Chip vayan a versar sobre este tema durante un tiempo. No. Junto con los posts de esta serie intercalaré artículos sobre otros temas completamente diferentes, para dar variedad y rebajar la ‘intensidad’.
Y hablo de intensidad porque, aunque intentaré hacer los posts lo más asequibles, sencillos, cortos y estructurados posible, no se trata de un tema sencillo y no puedo garantizar que siempre vaya a ser fácil hacerlos sencillos de entender.
Pero bueno, lo vamos a intentar.
Un comienzo curioso: los procesos de decisión de Markov
Y empiezo la serie de una forma que puede resultar sorprendente: hablando de procesos de decisión de Markov, una teoría ya bastante antigua y que, dicho así, puede parecer que no tiene nada que ver con el aprendizaje por refuerzo. Pero en seguida veremos que tiene muchísimo que ver.
Problemas de decisión secuenciales y el objetivo del aprendizaje por refuerzo
En efecto, siguiendo lo que indica Aske Plaat en el segundo capítulo de su libro, el aprendizaje por refuerzo se utiliza para resolver problemas de decisión secuenciales, es decir, procesos en que un agente (‘agent‘), tiene que adoptar una serie de decisiones o acciones en secuencia (una detrás de otra) hasta conseguir resolver el problema, un problema que se produce en un cierto entorno (‘environment‘) con el que el agente interactúa.
¿Y qué significa eso de ‘resolver’?
Pues, en este contexto, se trata de encontrar la serie de acciones a realizar por el agente que conduce a la mayor recompensa (‘reward‘) posible, por ejemplo, ganar una partida en un juego de mesa, o que un robot llegue de la forma más rápida posible a un cierto punto en el espacio.
No es casual del todo el que mencione como ejemplos un juego y un robot porque, en efecto, juegos y robots son dos campos muy importantes de aplicación del aprendizaje por refuerzo.
En el caso de los robots, mis seguidores más fieles pueden recordar el vídeo ‘Los conceptos de robot‘ de mi proyecto ‘The robot notes‘ en que acabo indicando que el concepto base para definir lo que es un robot es el de un agente inteligente artificial.
Estados y políticas
Cuando se modela un problema de este tipo hablamos de que el entorno puede estar en diferentes estados (por ejemplo, la posición de todas las piezas en un tablero de ajedrez).
El agente (por ejemplo el jugador humano o el programa de inteligencia artificial), puede tomar una serie de acciones (movimientos de las piezas permitidos) que cambian ese estado (la situación de las piezas cambia tras la acción y, por tanto, el estado), es decir, el entorno experimenta una transición de un estado a otro. Tras cada movimiento, el agente (el jugador) recibe una recompensa (sobre todo, si finalmente gana, aunque eventualmente se podría obtener una recompensa por una situación mas ventajosa).
El agente (el jugador) aplica una política (‘policy‘) que, dicho informalmente, podríamos decir que son los criterios para decidir su acción en un estado dado.
Y ya armados con este nuevo vocabulario, podemos decir que el aprendizaje por refuerzo busca encontrar la mejor política para operar en un entorno interactuando con él.
La propiedad de Markov
Pues bien, un proceso de decisión de Markov exhibe la denominada propiedad de Markov, a saber, que el estado siguiente sólo depende del estado actual y de las acciones disponibles para ese estado.
Lo que esto quiere decir es que no se guarda memoria de los estados anteriores ni se tiene ningún otro tipo de influencia.
Puede parecer o no que esta propiedad es muy restrictiva, pero lo cierto es que muchos casos prácticos reales se modelan con éxito con base en este tipo de procesos de decisión.
Elementos de un proceso de decisión de Markov
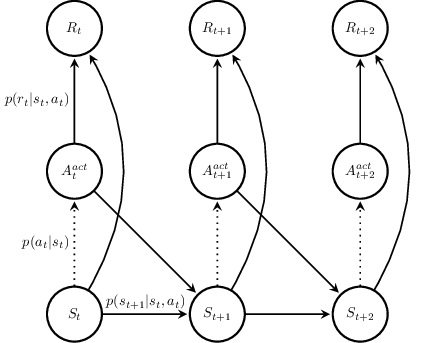
Con todo lo anterior, podemos identificar los cinco elementos que definen un proceso de decisión de Markov
- Estados: Un conjunto finito de estados legales. Cada estado define completamente la configuración de un entorno o problema en un momento dado.
- Acciones: Un conjunto finito de acciones aplicables, siendo potencialmente diferentes las acciones aplicables en cada estado.
- Transiciones: Indica la probabilidad, para todas las combinaciones posibles de estados y acciones, de que la aplicación de una acción concreta, en un estado concreto, haga cambiar (transicionar) al entorno del estado actual a otro estado diferente.
- Recompensas: Conjunto de recompensas, es decir, recompensa que recibe el agente para cada una de las transiciones de estado posibles.
- Factor de descuento: Que modula la, digamos, importancia de las recompensas recientes frente a las lejanas. Se trata de algo ya muy ligado al mecanismo de aprendizaje propiamente dicho.
Por supuesto, hay muchísimo más que contar de este tipo de procesos de decisión, y mucha formalización y formulación matemática que, al menos de momento, en este post he obviado en aras de la simplificación.
No descarto que tenga que ampliar más información en futuros artículos, pero de momento lo dejo aquí.
Conclusiones
Los algoritmos de aprendizaje por refuerzo trabajan con procesos de decisión secuenciales donde un agente interacciona con un entorno y donde existen unos estados del entorno, unas acciones disponibles para el agente, unos transiciones de estado en el entorno consecuencia de la aplicación de acciones y unas recompensas que obtiene el agente como resultado de esas transiciones.
Dentro de este tipo de problemas, son muy relevantes los procesos de decisión de Markov que, en esencia, se distinguen por que no tienen memoria ni tampoco influencias externas: solo dependen del estado y las acciones aplicables en cada momento.






3 comentarios